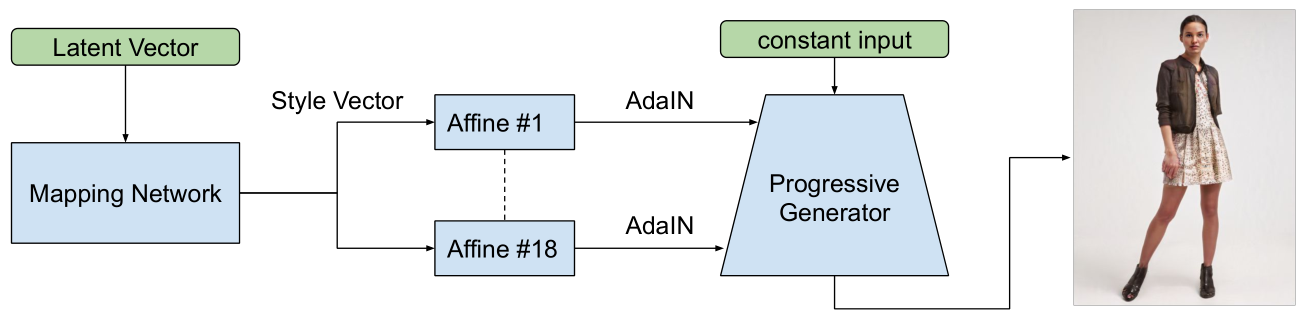
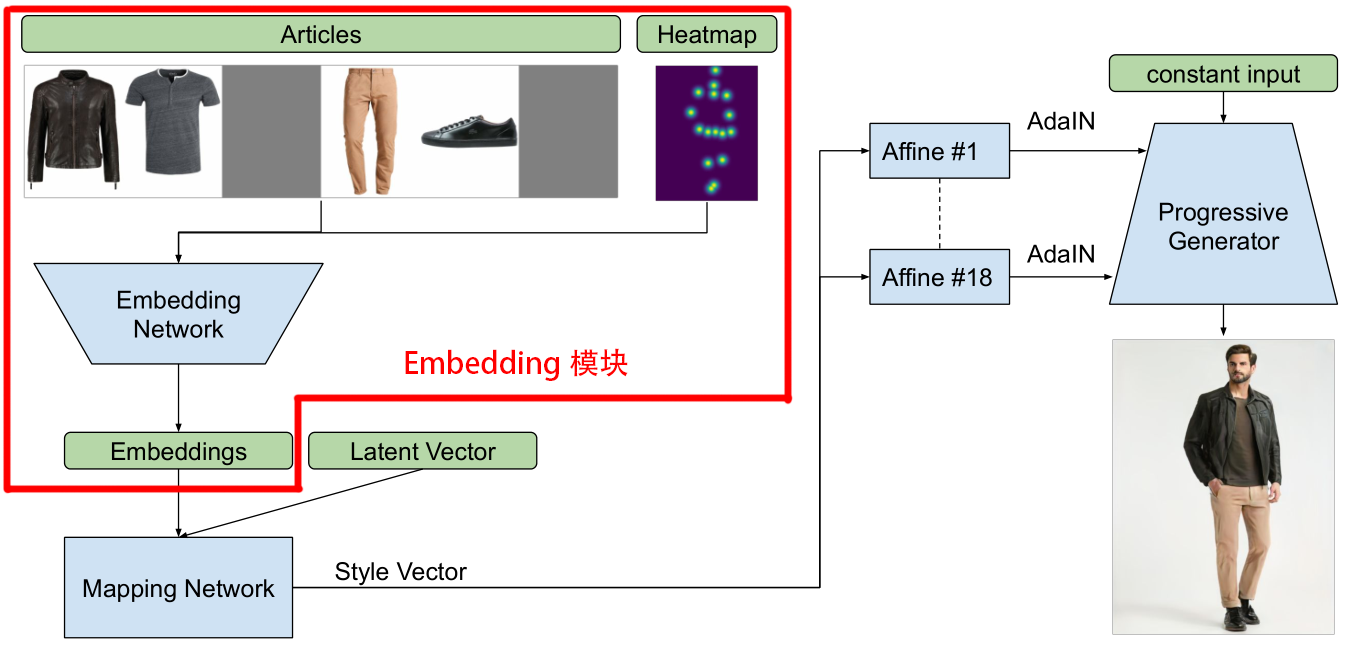
基于StyleGAN的含穿着的人物样貌生成
之前的工作都是聚焦于人脸生成方面的研究,这一节讲述StyleGAN在更多任务上的可能性的探索。我们有时会希望,StyleGAN能生成出一个更完整的人物出来,即它不仅仅包含人脸的部分,而是能生成一个含有穿着、姿态、打扮的完整人物样貌。这是一个复杂的任务,但是已经有研究机构取得了出色的效果(我没有参与其中,只是写笔记以学习)。下面将介绍19年8月份时由德国Zalando Research机构发表的论文Generating High-Resolution Fashion Model Images Wearing Custom Outfits。
实验有两方面的任务,第一个是无条件上的生成任务,也就是基于StyleGAN直接训练含着装的模特照片生成;第二个是有条件的生成任务,也就是依据条件限制,生成符合条件规定的着装以及姿态的模特照片。
图一 · 无条件生成任务的实验结果(取自paper)
图二 · 有条件生成任务的实验结果(取自paper)
可以看出,在无条件的生成任务上,生成的模特整体还是比较清晰、真实的,这也从侧面反应出StyleGAN能适应在更复杂数据集上的学习;而在有条件的生成任务上,生成结果既能达到清晰、真实的图片标准,也满足了对于穿着、姿态的定制化生成需求。下面我们将详细学习实验所采用的模型以及训练方法。
首先介绍一下实验所使用的数据集,如上图所示,数据集包含约 380K 条目的专有图像,其中每个条目都包含一个穿着特定服装、具有特定姿态的时装模特,加上一套包含最多6个物件的服装组合,其中身体姿态利用深度姿态估计器提取出的 16 个关键点表示(即模特身上的红点),在实验中以热图的形式记录。模特和物件图像都具有 1024×768 的分辨率。
如上图,在无条件生成任务上,采用的模型与StyleGAN基本一致,只是训练集换成了含着装的模特图片数据集。
如上图,在有条件生成任务上,模型额外引入了一个Embedding模块,其中Embedding Network的输入是18通道的服装部件图和16通道的姿态热图,输出是一个编码Embeddings,并且这个编码会与选用模特所对应的latent码一同传给Mapping Network,并由Mapping Network预测出新的自适应样式参数Style Vector,从而决定最终生成的模特的完整样貌。综上可以发现,实验的模型设计其实并不复杂,其中有条件任务上的模型设计与之前现实人脸编码时的模型设计思路有几分类似,证明这种设计方法在StyleGAN生成上是比较通用的,并且易于实现。
另外,从产品的角度来谈一点点拙见。之前GAN技术的主要应用集中在泛娱乐方面,不过这并不是GAN“溢价”最高的部分(因为对用户而言玩乐很有意思,但达不到持续付费的程度)。GAN技术的高溢价部分,长期来看会体现在结合推荐算法制作的数字生成内容广告,因为“某些人会受到某些样式的吸引”,这是GAN技术与广告属性完美贴合的地方。看看下面的例子就清楚了:
四组图是同样一套衣服的不同AI广告内容展示,其对于不同用户的吸引程度是因人而异的,比如我会喜欢2但有人喜欢4。因此,用AI生成零成本、个性化的广告,再结合推荐算法推送给不同喜好的个体,从而提升转化率,就恰恰是数字内容生成方案带来降本增效的地方。
含穿着人物的服装迁移、姿态变化与动作视频生成
一次偶然的实习经历让我意识到算法的真正价值应该体现为业务能力而不是技术价值,因此我花了半年时间去尝试了更接地气的技术方向——视频擦除,它是基于生成技术面向视频场景的落地应用。我非常诚挚地邀请您前往第三页了解一下我在这个方面所做的探索,我认为它会为您带来新的视角上的帮助,以及更全面的关于生成技术的了解。