多模态生成
多模态生成是指多种模态信息输入到单/多模态信息输出的过程,譬如一段文本+人物图像的输入,模型输出人物念对应文本的合成视频,即为跨图像和文本两种模态信息的多模态生成的范例。多模态生成是一种极有价值的研究方向,简单来说,将多种模态的信息(譬如语音、文本、表情等)融入生成模型能更多维度地提取信息,有利于增强生成图像的控制能力和表意能力,带来更多元的业务场景。
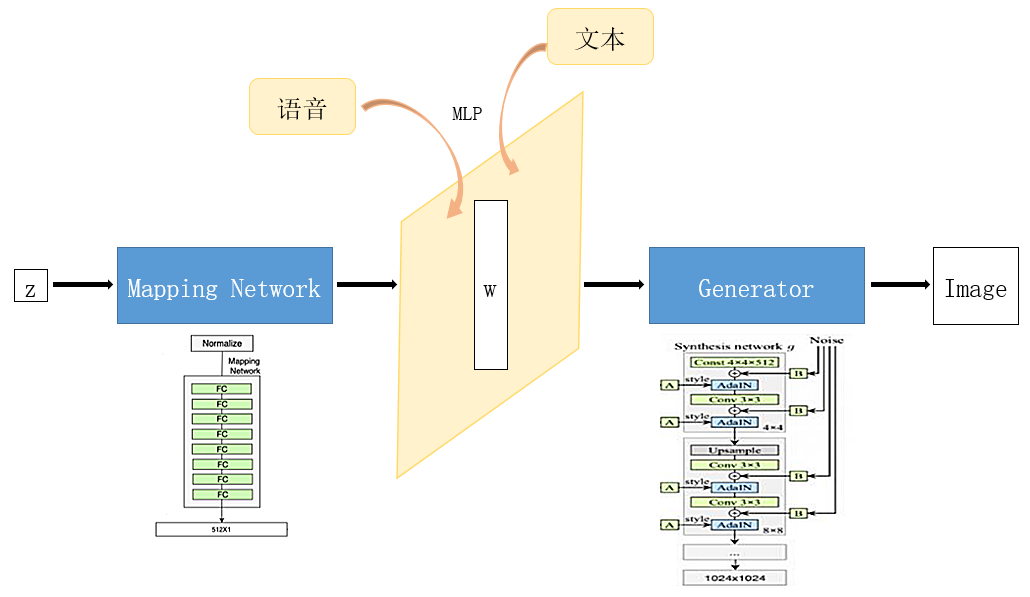
对于StyleGAN而言有两点非常适用于多模态生成的优势。第一点是StyleGAN所构建的映射并不是低维编码到图像的直接映射,而是构建了从低维编码到中间向量(W)的过渡映射,然后再映射到最终图像,因此中间向量分布宽度是足够大的(不需要服从正态分布的先验),于是W空间可作为多模态对齐和变换的操作潜空间;第二点是潜空间(W)到图像的映射方式是自适应实例归一化(AdaIN),AdaIN具有很灵活的调节功能,对于多模态融合的信息有较好的仿射拟合能力。
多模态生成样例:一种基于文本控制的图像生成模型——StyleCLIP
譬如StyleCLIP就是一项非常有意思的工作,其将文本控制能力引入进了StyleGAN之中,使图像生成变得更易于控制和具有更丰富的功能。
工作啦
读研时光飞快,不知不觉就要参与工作了,后续的研究内容没法再对外写出了,有缘在产品的江湖再会吧。
回顾我的读研三年时间,感觉自己蛮奇葩的:三年时间做过多种项目,但凭着较浓的兴趣也抽空捣鼓了不少与生成技术有关的博客和开源代码。我逐渐对AI有一种看法:AI的本质是盘数据的逻辑,因此我不看好人们在理解AI方面做出的尝试,因为理解数据逻辑对人类来说本身已经是超纲的事情,用数学推导去解释无法严谨也没必要。所以,我更倾向于将AI当做达成目的的工具使用,我们对于模型搭建的设计有多巧妙取决于我们对于数据逻辑的感知有多精准。所以,AI的本源是工程。人生苦短,不妨硬训一发。